爬虫是 Python 的一个常见应用场景,很多练习项目就是让大家去爬某某网站。爬取网页的时候,你大概率会碰到一些反爬措施。这种情况下,你该如何应对呢?本文梳理了常见的反爬措施和应对方案。
”python 反爬机制“ 的搜索结果
转载这篇文章主要是了解python反爬虫策略,帮助自己更好的理解和使用python 爬虫。
一、常见反爬机制及其破解方式 二、调用三方API接口数据(天行数据) 三、OCR(光学文字识别)库 四、第三方打码平台(超级鹰打码平台) 五、通过接码平台接收手机验证码(隐私短信平台) 仅提供参考思路,网站在不断...
Python爬虫基础知识和反爬机制(案例) Python爬虫基础知识和反爬机制(案例) Python爬虫基础知识和反爬机制(案例) Python爬虫基础知识和反爬机制(案例) Python爬虫基础知识和反爬机制(案例) Python爬虫基础...
识别验证码 OCR(Optical Character Recognition)即光学字符识别技术,专门用于对图片文字进行识别,并获取文本。字符验证码的特点就是验证码中包含数字、字母或者掺杂着斑点与混淆曲线的图片验证码。...
profile.set_preference(‘network.proxy.http’, proxy_ip) # http 代理。profile.set_preference(‘network.proxy.ssl’, proxy_ip) # https 代理。profile.add_extension(xpi) # 添加扩展。返回的就是代理 ip。
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套...
Python爬虫是一个强大的工具,可以用于获取互联网上的各种信息。然而,随着反爬机制的不断发展,爬虫开发者需要不断学习和更新知识,以应对各种挑战。同时,也要遵守法律法规和网站的使用协议,尊重他人的权益。
我们在进行网络爬虫的时候经常会碰到一些不理解的问题,除去语法错误和运行时错误,其余导致我们的爬虫出现问题的就是网站的反爬机制,本文将专门地介绍几种常规性的反爬机制以及其所对应的解决办法(^・ω・^)
python爬虫基础知识、爬虫实例、反爬机制等资源分享.rar python爬虫基础知识、爬虫实例、反爬机制等资源分享.rar python爬虫基础知识、爬虫实例、反爬机制等资源分享.rar
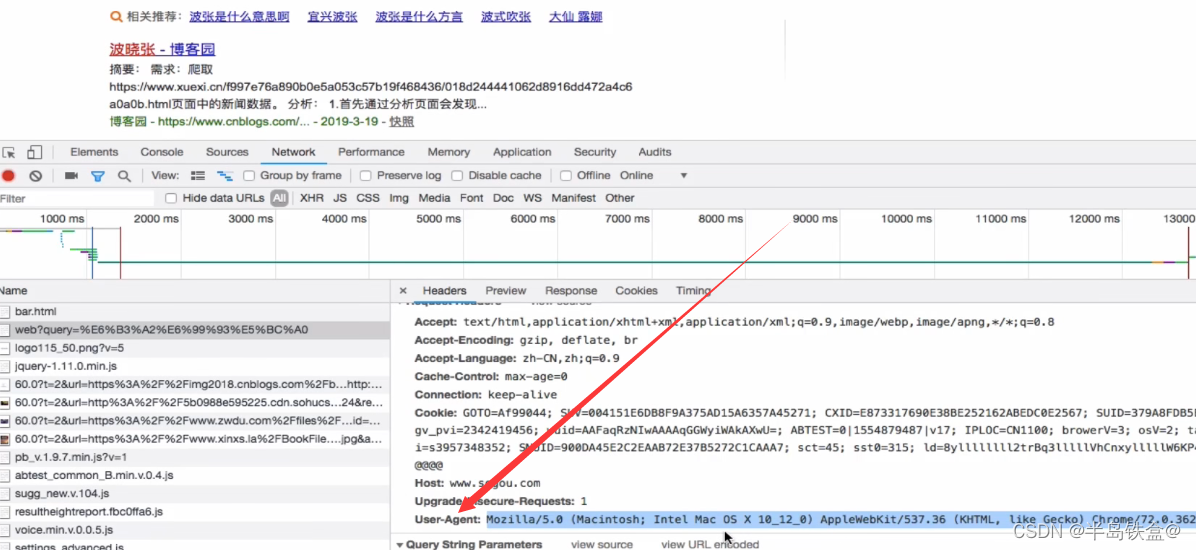
用浏览器打开 https://httpbin.org/headers 网站,将会看的下面的页面,这就是该浏览器...将上面的请求头复制下来,传给函数,即可将请求伪装成浏览器。在应用爬虫的时候,可以随机跟换其他 User-Agent 避免触发反爬。
1.反爬的诞生网络爬虫,是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。但是一旦网络爬虫被滥用,互联网上就会出现太多形似同质,换汤不换药的内容,使得原创得不到保护。于是...
Python常见反爬虫机制解决方案2、时间设置适用情况:限制频率情况。Requests,Urllib2都可以使用time库的sleep()函数:import timetime.sleep(1)3、伪装成浏览器,或者反“反盗链”有些网站会检查你是不是真的浏览器...
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!朋友们如果需要可以微信扫描下方CSDN官方...
详情见维基百科词条:[User agent]对于有反爬的网站会识别其 headers 从而拒绝返回正确的网页。此时需要对发送的请求伪装成浏览器的 headers。用浏览器打开 https://httpbin.org/headers 网站,将会看的下面的页面,...

本文实例讲述了python3爬虫学习之应对网站反爬虫机制的方法。分享给大家供大家参考,具体如下:如何应对网站的反爬虫机制在访问某些网站的时候,网站通常会用判断访问是否带有头文件来鉴别该访问是否为爬虫,用来...
将上面的请求头复制下来,传给函数,即可将请求伪装成浏览器。在应用爬虫的时候,可以随机跟换其他 User-Agent 避免触发反爬。
关于Python爬虫基础知识、爬虫实例和反爬机制 # Python爬虫基础知识 ## 什么是爬虫? 爬虫(也称为网络爬虫、网页抓取器)是一种自动化程序,用于从互联网上收集信息。它们通过HTTP请求访问网页,并从网页中提取...
python3爬虫--反爬虫应对机制内容来源于:前言:反爬虫更多是一种攻防战,网络爬虫一般有网页爬虫和接口爬虫的方式;针对网站的反爬虫处理来采取对应的应对机制,一般需要考虑以下方面:①访问终端限制:这种可通过...
使用代理绕过网站的反爬机制
标签: python
最近在尝试收集一些网络指标的数据, 所以, 我又开始做爬虫了。:)我们在做爬虫的过程中经常会遇到这样的情况,最初爬虫正常运行,正常抓取数据,一切看起来都是那么的美好,然而一杯茶的功夫可能就会出现错误,比如...
本文将介绍Python爬虫的基础知识、示例以及常见的反爬机制。 ### Python爬虫基础知识 #### 什么是爬虫? 爬虫,又称网络爬虫或网页抓取器,是一种自动化程序,用于从互联网上收集信息。它们通过HTTP请求访问网页...
书本上说有,烟花是火药的前身,谁能想到一个美丽的事物,最后会被用于战争呢?就像我们最早只为为了获取一些数据,来加强一个信息资源的快速更新,最后因为种种原因,又需要一种阻止这种大批获取数据的行为。...
title: python实战爬虫有道翻译与解决有道...与教程中不一样的是现在的有道翻译有了反爬虫机制,最后通过查询百度与借鉴其他人的博客实现~tags:随笔Python学习前言:不需要打开有道翻译网页就能在本地使用,还是很方...
一、 UA 限制 二、 懒加载 三、 Cookie
掌握爬虫遇到的五大类情况,精准对比遇到的反爬机制。
这篇文章详尽地介绍了Python爬虫的基础知识、实例应用以及反爬机制等内容,为初学者和有经验的开发者提供了宝贵的参考资源。 在基础知识部分,文章深入浅出地讲解了爬虫的工作原理,包括HTTP请求与响应的发送与接收...
(相关阅读推荐:Python学习就看这里!)爬虫是什么呢,简单而片面的说,爬虫就是由计算机自动与服务器交互获取数据的工具。爬虫的最基本就是get一个网页的源代码数据,如果更深入一些,就会出现和网页进行POST交互,...
内容概要:Python爬虫系列课程,共10个章节,深入浅出掌握Python爬虫的基础知识,了解爬虫实例,熟悉反爬机制,小的系列课程。 适合人群:基础小白入门系列,想了解Python爬虫基础知识的同学,属于入门级课程,可以...
推荐文章
- Unity3D 导入资源_unity怎么导入压缩包-程序员宅基地
- jqgrid 服务器端验证,javascript – jqgrid服务器端错误消息/验证处理-程序员宅基地
- 白山头讲PV: 用calibre进行layout之间的比对-程序员宅基地
- java exit方法_Java:如何测试调用System.exit()的方法?-程序员宅基地
- 如何在金山云上部署高可用Oracle数据库服务_rman target sys/holyp#ssw0rd2024@gdcamspri auxilia-程序员宅基地
- Spring整合Activemq-程序员宅基地
- 语义分割入门的总结-程序员宅基地
- SpringBoot实践(三十五):JVM信息分析_怎样查看springboot项目的jvm状态-程序员宅基地
- 基于springboot+vue的戒毒所人员管理系统 毕业设计-附源码251514_戒毒所管理系统-程序员宅基地
- 【LeetCode】面试题57 - II. 和为s的连续正数序列_leet code 和为s的正数序列 java-程序员宅基地